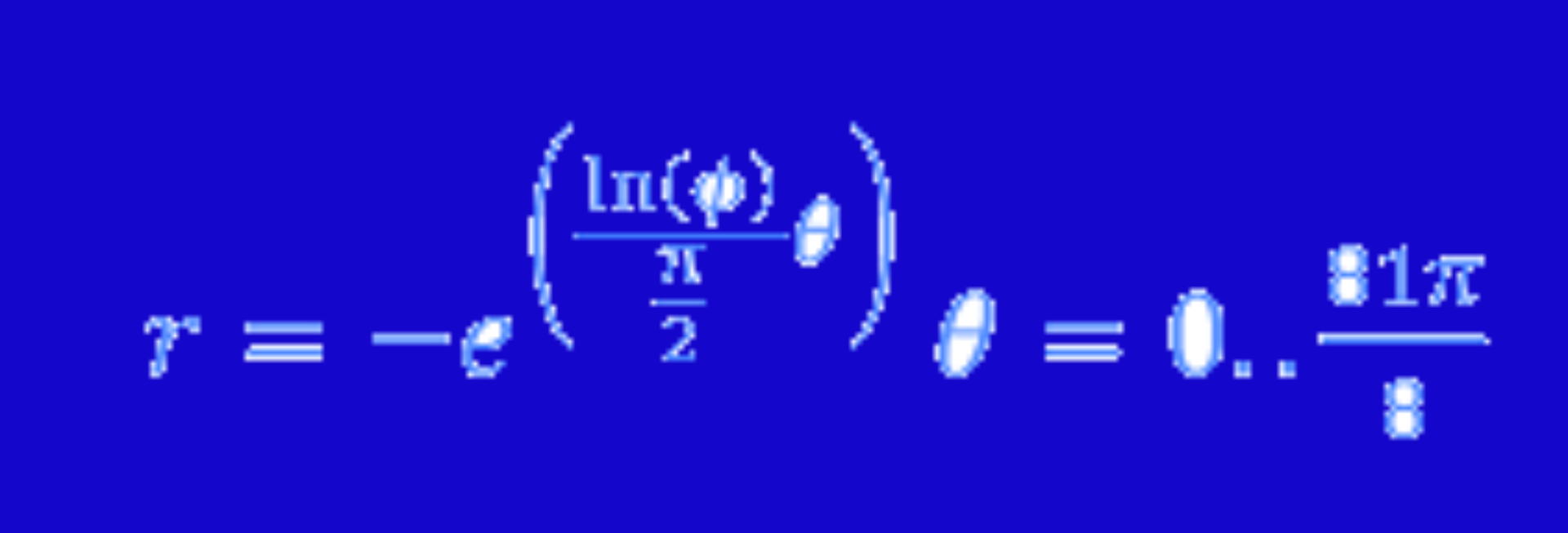A Decade Long Problem
Back in 1998, I overheard my high school math teacher musing to another teacher about the following problem:
Given a line segment of unit length, select any two points to cut the line into three parts. What is the probability that the resulting three line segments will form a “good” triangle.
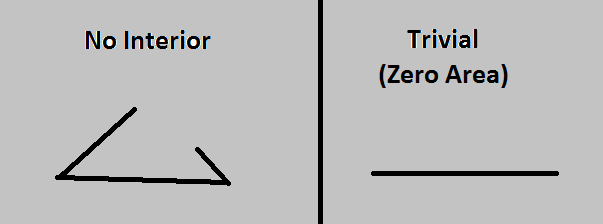 By a “good” triangle, he meant one which completely encloses a non-zero area. That is, if the longest side is longer than the sum of the other two sides, it’s impossible to use those three segments to enclose an area. The trivial case exists where the longest side is equal to the sum of the shorter sides, but this triangle encloses no area.
By a “good” triangle, he meant one which completely encloses a non-zero area. That is, if the longest side is longer than the sum of the other two sides, it’s impossible to use those three segments to enclose an area. The trivial case exists where the longest side is equal to the sum of the shorter sides, but this triangle encloses no area.
A Delayed Response
Several years later, after I had learned to program myself, I wrote a Monte Carlo algorithm to simulate this situation, but much to my dismay, after 1000 trials, I got a probability of a little more than 


Renewed Strength
Many years later, in 2007, after graduate school, I decided to approach the problem from a theoretical perspective, and after some fumbling around in an attempt to create a probability distribution function, an insight from a former professor lit my path. He suggested that I think of the cuts as a two-dimensional x-y graph, where any point ")


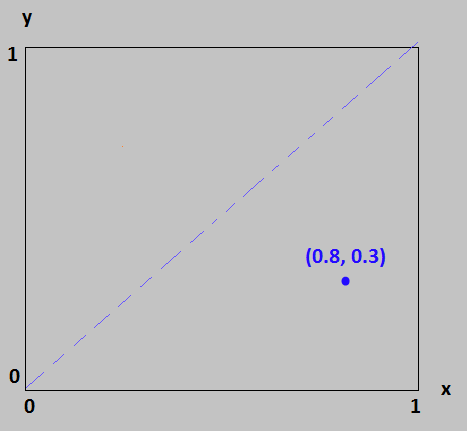 Assuming the line segment is of unit length, then the two cuts,
Assuming the line segment is of unit length, then the two cuts, ")
")




This was useful because now I could analyze the graph for the regions which create good triangles, and the ones which create bad ones. I started by considering how the cuts might go awry. The simple answer is that any time one of the segments is larger than
Segment 









 The bounds described above are labeled with the corresponding line segment and I provided the value of each bounded area for reference. It was then fairly easy to see that each offending segment reduces the overall “good” area in the graph by
The bounds described above are labeled with the corresponding line segment and I provided the value of each bounded area for reference. It was then fairly easy to see that each offending segment reduces the overall “good” area in the graph by 
Time To Get Serious
Recently, and after a few years of experience as a software developer, I decided to rewrite the simulation in C#. Whereas once it took me a full day to write, I was now able to reproduce it in a few minutes. Here is the core of my rewrite:
for (int i = 0; i < numberOfCuts; ++i)
{
List<double> sides = new List<double>();
double firstCut = rng.NextDouble();
double secondCut = rng.NextDouble();
double lowCut = Math.Min(firstCut, secondCut);
double highCut = Math.Max(firstCut, secondCut);
sides.Add(lowCut);
sides.Add(highCut - lowCut);
sides.Add(1.0 - highCut);
sides.Sort();
if (sides[0] + sides[1] < sides[2])
{
bad++;
}
else
{
good++;
}
}
To my delight, after 

For efficiency pedants, I will concede that instead of checking the sum in the “if” condition above, I could simply check that the longest side does not exceed
A New Challenger Emerges
To create a slightly more interesting problem, I imposed the restriction that the first cut alone is responsible for defining segment
Well, now that I had a working simulation, I only really needed to change one line of code to account for this new criterion. Instead of generating a random number between zero and one for the 
double secondCut = rng.NextDouble();
becomes
double secondCut = firstCut + (1 - firstCut) * rng2.NextDouble();
After running this slightly modified algorithm over 

To confirm the new solution, I simply calculated it the old fashioned way, primarily because the geometric solution is not nearly as obvious for this problem, which we’ll see later. Let me reproduce that logic for you:
Again, I considered the bad regions first, and ruled them out. Of course, any cut where 


What is the probability of 
")
")

 = \frac{0.5 + x_{0} - 0.5}{1 - x_{0}} = \frac{x_{0}}{1-x_{0}}")
But I’m not interested in a single value of

And with the nifty substitution 
![\int_{0.5}^{1} \! \frac{1-r}{r} \, \mathrm{d} r = [ln|r| - r]_{0.5}^1 = (0 - 1) - (ln(\frac{1}{2}) - \frac{1}{2}) = ln(2) - \frac{1}{2}](https://web.archive.org/web/20160415040150im_/http://s0.wp.com/latex.php?latex=%5Cint_%7B0.5%7D%5E%7B1%7D+%5C%21+%5Cfrac%7B1-r%7D%7Br%7D+%5C%2C+%5Cmathrm%7Bd%7D+r+%3D+%5Bln%7Cr%7C+-+r%5D_%7B0.5%7D%5E1+%3D+%280+-+1%29+-+%28ln%28%5Cfrac%7B1%7D%7B2%7D%29+-+%5Cfrac%7B1%7D%7B2%7D%29+%3D+ln%282%29+-+%5Cfrac%7B1%7D%7B2%7D&bg=ffffff&fg=000&s=0 "\int_{0.5}^{1} \! \frac{1-r}{r} \, \mathrm{d} r = [ln|r| - r]_{0.5}^1 = (0 - 1) - (ln(\frac{1}{2}) - \frac{1}{2}) = ln(2) - \frac{1}{2}")
It will probably not surprise you that this evaluates to 
One Final Piece To Explain
Now that I know the equations of the boundaries, I can look at how the graph has changed.

Notice that, since there is now a restriction on 
As it turns out, the graph above is technically correct in that, given the stated conditions, it represents every possible pair of cuts that will yield a good triangle. The reason the actual probability is higher is simply that the distribution is no longer uniform. That is, certain points in the “good” area are actually more likely to be sampled than points in the “bad” space. This is because of the fact that an increasing value of 

What I Learned
Although it’s somewhat embarrassing that it took a student with a graduate degree in mathematics fourteen years to solve what amounts to a fairly simple probability problem, I enjoy sharing it because it reminds me of the frustration and reward of mathematics. Certainly whatever you love to do has made you feel the same, so I hope you enjoyed my story too.